Finetuning Transformers on GLUE benchmark
Compare transformer models on sequence classification uisng GLUE benchmark with WandB experiment logging and more


- Introduction
- Setup
- Running a GLUE task
- Another task example: MNLI
- Low resource tasks
- Concluding thoughts
from transformers import AutoModelForSequenceClassification
from fastai.text.all import *
from fastai.callback.wandb import *
from fasthugs.learner import TransLearner
from fasthugs.data import TransformersTextBlock, TextGetter, get_splits
from datasets import load_dataset, concatenate_datasets
import wandb
import gc
Introduction
In this blogpost we will look at how to combine the power of HuggingFace with great flexibility of fastai. For this purpose we will finetune distilroberta-base on The General Language Understanding Evaluation(GLUE) benchmark. GLUE consists of 8 diverse sequence classification and one regression task.
I'll use fasthugs to make HuggingFace+fastai integration smooth.
Fun fact:GLUE benchmark was introduced in this paper in 2018 as tough to beat benchmark to chellange NLP systems and in just about a year new SuperGLUE benchmark was introduced because original GLUE has become too easy for the models. To give you a grasp on what we are dealing with, here is a brief summary of GLUE tasks:
As you can see some datasets are really small here. And we'll look at how one can adress.
Let's define main settings for the run in one place:
ds_name = 'glue'
model_id = "distilroberta-base"
model_name = model_id.split("/")[-1]
max_len = 512
bs = 32
val_bs = bs*2
n_epoch = 4
lr = 2e-5
wd = 0.
opt_func = Adam
diff_lr_decay_factor = 0
To make switching between datasets smooth I define couple of dictionaries containing per-task information. We need metrics, text fields to retrieve data and number of outputs for the model.
GLUE_TASKS = ["cola", "mnli", "mrpc", "qnli", "qqp", "rte", "sst2", "stsb", "wnli"]
def validate_task():
assert task in GLUE_TASKS
glue_metrics = {
'cola':[MatthewsCorrCoef()],
'sst2':[accuracy],
'mrpc':[F1Score(), accuracy],
'stsb':[PearsonCorrCoef(), SpearmanCorrCoef()],
'qqp': [F1Score(), accuracy],
'mnli':[accuracy],
'qnli':[accuracy],
'rte': [accuracy],
'wnli':[accuracy],
}
glue_textfields = {
'cola':['sentence', None],
'sst2':['sentence', None],
'mrpc':['sentence1', 'sentence2'],
'stsb':['sentence1', 'sentence2'],
'qqp': ['question1', 'question2'],
'mnli':['premise', 'hypothesis'],
'qnli':['question', 'sentence'],
'rte': ['sentence1', 'sentence2'],
'wnli':['sentence1', 'sentence2'],
}
glue_num_labels = {'mnli':3, 'stsb':1}
def layerwise_splitter(model):
emb = L(model.base_model.embeddings)
layers = L(model.base_model.encoder.layer.children())
clf = L(m for m in list(model.children())[1:] if params(m))
groups = emb + layers + clf
return groups.map(params)
task = 'sst2'; validate_task()
ds = load_dataset(ds_name, task)
valid_ = 'validation-matched' if task=='mnli' else 'validation'
len(ds['train']), len(ds[valid_])
train_idx, valid_idx = get_splits(ds, valid=valid_)
train_ds = concatenate_datasets([ds['train'], ds[valid_]])
train_ds[0]
Here I use number of characters a proxy for length of tokenized text to speed up dls creation.
lens = train_ds.map(lambda s: {'len': sum([len(s[i]) for i in glue_textfields[task] if i])},
remove_columns=train_ds.column_names, num_proc=2, keep_in_memory=True)
train_lens = lens.select(train_idx)['len']
valid_lens = lens.select(valid_idx)['len']
blocks = [TransformersTextBlock(pretrained_model_name=model_id),
RegressionBlock() if task=='stsb' else CategoryBlock()]
dblock = DataBlock(blocks = blocks,
get_x=TextGetter(*glue_textfields[task]),
get_y=ItemGetter('label'),
splitter=IndexSplitter(valid_idx))
dl_kwargs=[{'res':train_lens}, {'val_res':valid_lens}]
dls = dblock.dataloaders(train_ds, bs=bs, val_bs=val_bs, dl_kwargs=dl_kwargs)
dls.show_batch(max_n=4)
The GLUE benchmark contains 8 tasks and it might be cumbersome to systematize the results. To make the analysis simpler and much more powerful I will be using Weights&Biases tracking platform.
And even better thanks to Morgan McGuire (@morg) we have an open W&B project. You just need to log your runs under glue-benchmark project and set entity="fastai_community" and your results will be added to the pull for further investigation of hyperparameters. The fastest way to start participating would be to fork this notebook as it is set up to run any of the GLUE tasks with minimal changes.
There is a lot to try: gradual unfreezing strategy is reported not to be helpful when finetuning Transformer-based models (for example see a discussion here); differential learning rates are used in NLP [1, 2] but are not common practice, do we need to use weight decay, if yes - how much and where, what suggestions from LR-finder work best? These are only few of many open questions and there are so much more.
And even more interesting one how do this scale with dataset and model size?
Deep Learning as of now is highly empirical field and experiments require both some engendering and compute. This post is aimed to fuel community effort towards finding empirical truth by joining small forces together. Even if you're new to NLP do not hesitate to participate and run couple of experiments while learning along the way!
WANDB_NAME = f'{ds_name}-{task}-{model_name}'
GROUP = f'{ds_name}-{task}-{model_name}-{lr:.0e}'
if diff_lr_decay_factor: GROUP += f"diff_lr_{diff_lr_decay_factor}"
NOTES = f'finetuning {model_name} with {opt_func.__name__} lr={lr:.0e}'
TAGS =[model_name, ds_name, opt_func.__name__]
wandb.init(reinit=True, project="glue-benchmark", entity="fastai_community",
name=WANDB_NAME, group=GROUP, notes=NOTES, tags=TAGS);
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=glue_num_labels.get('task', 2))
metrics = glue_metrics[task]
learn = TransLearner(dls, model, metrics=metrics, opt_func=opt_func, splitter=layerwise_splitter)
if diff_lr_decay_factor != 0:
k = len(layerwise_splitter(model))
lr = slice(lr*diff_lr_decay_factor**k,lr)
metric_to_monitor = metrics[0].name if isinstance(metrics[0], Metric) else metrics[0].__name__
cbs = [WandbCallback(log_preds=False, log_model=False),
SaveModelCallback(monitor=metric_to_monitor, fname=f'{model_name}-{task}')]
learn.fit_one_cycle(4, lr, wd=wd, cbs=cbs)
It's always useful to check your model predictions after training. fastai makes this very simple:
learn.show_results()
Finding the perfect learning rate for a task isn't easy. Add weight decay, different optimizers, differential learning rates and various scheduler to the mix and search for the best hyperparameters becomes a really big task. For that reason there exist automated tools for hyperparameter search. Here we'll look at sweeps functionality provided by W&B.
It not only facilitates hyperparameter finetuning but also enables great visualization of the results, which might help for further analysis. Check out documentaion for more details.
def train():
with wandb.init() as run:
cfg = run.config
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=glue_num_labels.get(task, 2))
metrics = glue_metrics[task]
k = len(layerwise_splitter(model))
if cfg.diff_lr_decay_factor: lr = slice(cfg.lr*cfg.diff_lr_decay_factor**k,cfg.lr)
learn = TransLearner(dls, model, metrics=metrics, opt_func=Adam, splitter=layerwise_splitter)
learn.fit_one_cycle(n_epoch, cfg.lr, wd=cfg.wd, cbs=[WandbCallback(log_preds=False, log_model=False)])
del learn
gc.collect()
torch.cuda.empty_cache()
torch.cuda.synchronize()
Here we'll do a grid search over combinations of learning rate, weight decay and differential learning rates. Differential learning rates is specified by decay factor $\gamma$: $lr$ for layer $l$ are are determined as ${lr_0}*\gamma^{L-l}$, where L is total number of layers.
metrics = glue_metrics[task]
metric_to_monitor = metrics[0].name if isinstance(metrics[0], Metric) else metrics[0].__name__
sweep_name = f"glue-{task}-sweep"
sweep_config = {
"project":"glue-benchmark",
"entity":"fastai_cimmunity",
"name": sweep_name,
"method": "grid",
"parameters": {
"lr": {"values":[1e-5,2e-5,3e-5,5e-5, 1e-4]},
"wd": {"values":[0.,1e-2,5e-2]},
"diff_lr_decay_factor":{"values":[0., 0.9, 0.8, 0.7, 0.6]}
},
"metric":{"goal": "maximise", "name": metric_to_monitor},
"early_terminate": {"type": "hyperband", "s": 2, "eta": 3, "max_iter": 40}
}
sweep_id = wandb.sweep(sweep_config)
wandb.agent(sweep_id, function=train)
As a result we get a nice chart which helps to relate hyperparameter combinations to model performance.
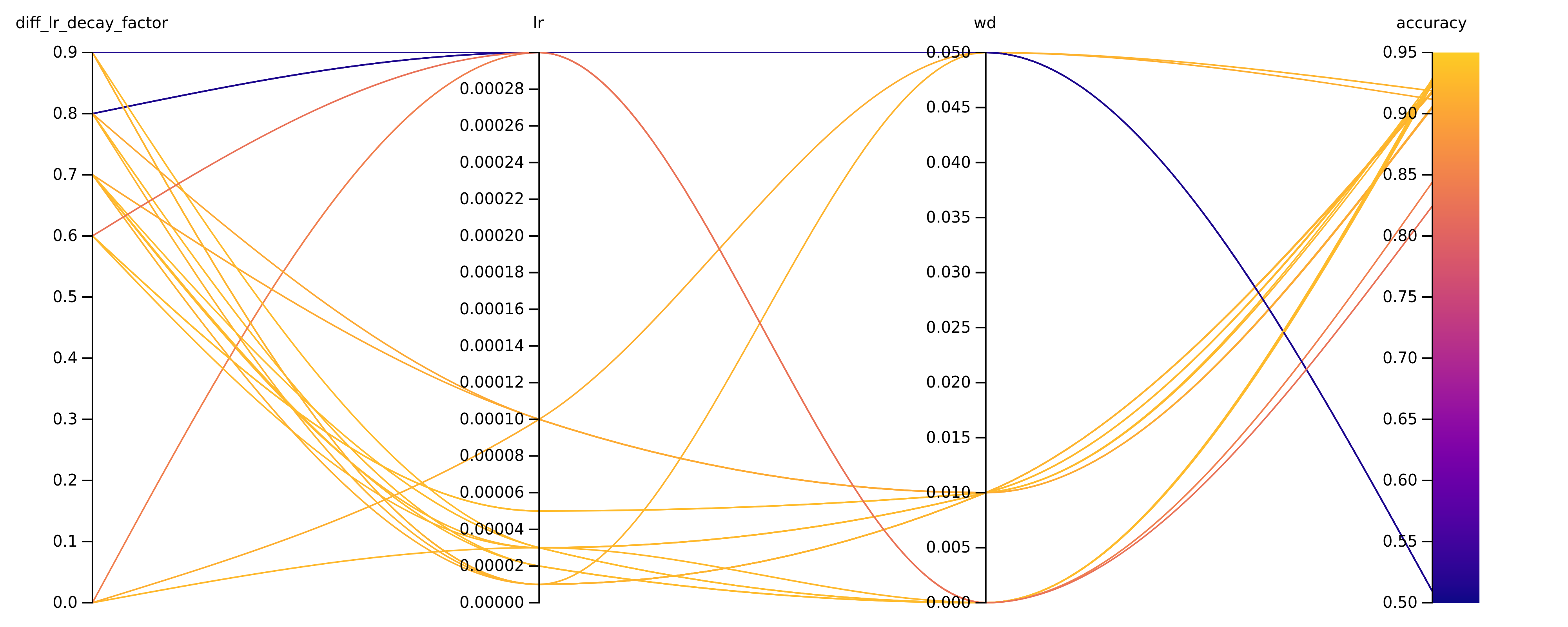
The sweep can be explored interactively by this link https://wandb.ai/fastai_community/glue-benchmark/sweeps/hc8ytty4.
Another task example: MNLI
MNLI task is interesting for a couple of reasons. It has the largest training set in the benchmark, for the results of training for MNLI might be useful for smaller tasks as we will consider in the next section. Unlike most of the GLUE tasks, which ar formulated as binary classification problem, this one has three categories: entailment, neutral and contradiction. One can argue that solving such kind of problem should envolve more "understanding" of the meaning of text.
task = 'mnli'; validate_task()
ds = load_dataset(ds_name, task)
train_idx, valid_idx = get_splits(ds, valid='validation_matched')
train_ds = concatenate_datasets([ds['train'], ds['validation_matched']])
Each sample contains premise and hypothesis, the task is to determine whether the hypothesis entails, contradicts or is neutral to the premise. Let's check out an example:
train_ds[0]
The data preparation and dataloaders construction do not differ much from those for previous task:
lens = train_ds.map(lambda s: {'len': len(s['premise'])+len(s['hypothesis'])}, remove_columns=train_ds.column_names, num_proc=4, keep_in_memory=True)
train_lens = lens.select(train_idx)['len']
valid_lens = lens.select(valid_idx)['len']
blocks = [TransformersTextBlock(pretrained_model_name=model_id),
RegressionBlock() if task=='stsb' else CategoryBlock()]
dblock = DataBlock(blocks = blocks,
get_x=TextGetter(*glue_textfields[task]),
get_y=ItemGetter('label'),
splitter=IndexSplitter(valid_idx))
dl_kwargs=[{'res':train_lens}, {'val_res':valid_lens}]
dls = dblock.dataloaders(train_ds, bs=bs, val_bs=val_bs, dl_kwargs=dl_kwargs, num_workers=4)
dls.show_batch(max_n=4)
WANDB_NAME = f'{ds_name}-{task}-{model_name}'
GROUP = f'{ds_name}-{task}-{model_name}-{lr:.0e}'
NOTES = f'finetuning {model_name} with Adam lr={lr:.0e}'
TAGS =[model_name, ds_name, 'adam', task]
wandb.init(reinit=True, project="glue-benchmark", entity="fastai_community",
name=WANDB_NAME, group=GROUP, notes=NOTES, tags=TAGS);
Training procedure is also very similar:
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=3)
metrics = glue_metrics[task]
learn = TransLearner(dls, model, metrics=metrics)
metric_to_monitor = metrics[0].name if isinstance(metrics[0], Metric) else metrics[0].__name__
cbs = [WandbCallback(log_preds=False, log_model=False),
SaveModelCallback(monitor=metric_to_monitor, fname=f'{model_name}-{task}')]
learn.fit_one_cycle(4, lr, wd=wd, cbs=cbs)
learn.show_results()
MNLI task has another missmatched validation set. matched set contains in-domain data and the missmatched is a cross-domain.
valid_mm_dl = dls.test_dl(ds['validation_mismatched'], with_labels=True)
learn.validate(dl=valid_mm_dl)
Notice that there are similar datasets available (e.g. snli dataset). Those might be used to improve the performance. But for these post I'll limit the scope to GLUE data only and leave the experiments with extra data for upcoming posts.
Some daatsets are rather small, RTE has only 2.5k samples in the training set. This is not much at all for nontrivial language task like this one. But we can try to use a small trick to improve the results. The MNLI task is quite similar and has much more training data. Let's reuse model trained on it for improving RTE score. This trick is common practice and has been employed in original RoBERTa paper when reporting GLUE score.
task = 'rte'; validate_task()
ds = load_dataset(ds_name, task)
valid_ = 'validation-matched' if task=='mnli' else 'validation'
len(ds['train']), len(ds[valid_])
train_idx, valid_idx = get_splits(ds, valid=valid_)
train_ds = concatenate_datasets([ds['train'], ds[valid_]])
train_ds[0]
blocks = [TransformersTextBlock(pretrained_model_name=model_name),
RegressionBlock() if task=='stsb' else CategoryBlock()]
dblock = DataBlock(blocks = blocks,
get_x=TextGetter(*glue_textfields[task]),
get_y=ItemGetter('label'),
splitter=IndexSplitter(valid_idx))
dls = dblock.dataloaders(train_ds, bs=bs, val_bs=val_bs)
dls.show_batch(max_n=4)
WANDB_NAME = f'{ds_name}-{task}-{model_name}'
GROUP = f'{ds_name}-{task}-{model_name}-{lr:.0e}'
if diff_lr_decay_factor: GROUP += f"diff_lr_{diff_lr_decay_factor}"
NOTES = f'finetuning {model_name} with {opt_func.__name__} lr={lr:.0e}'
TAGS =[model_name, ds_name, opt_func.__name__]
wandb.init(reinit=True, project="fasthugs", entity="fastai_community",
name=WANDB_NAME, group=GROUP, notes=NOTES, tags=TAGS);
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=glue_num_labels.get('task', 2))
metrics = glue_metrics[task]
learn = TransLearner(dls, model, metrics=metrics, opt_func=opt_func)
try:
learn.load('distilroberta-base-mnli', with_opt=False, strict=False)
except RuntimeError as e:
print(e)
if diff_lr_decay_factor != 0:
k = len(layerwise_splitter(model))
lr = slice(lr*diff_lr_decay_factor**k,lr)
metric_to_monitor = metrics[0].name if isinstance(metrics[0], Metric) else metrics[0].__name__
cbs = [WandbCallback(log_preds=False, log_model=False),
SaveModelCallback(monitor=metric_to_monitor, fname=f'{model_name}-{task}')]
learn.fit_one_cycle(10, lr, wd=wd, cbs=cbs, pct_start=0.1)
As one can see by using this simple trick we've improved the result reported at HuggingFace model card by some 10%. Pretty nice, ha?
Just to be sure that improvement is due to using model finetuned on mnli let's do another run starting from vanilla distilroberta:
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=glue_num_labels.get('task', 2))
metrics = glue_metrics[task]
learn = TransLearner(dls, model, metrics=metrics, opt_func=opt_func)
learn.fit_one_cycle(10, lr, wd=wd, cbs=cbs, pct_start=0.1)
The same is applicable for STSB taks, which has 7k training samples. Performance gain for STSB is not so prominent but it's still there. You can compare the results for cold and warm starts in this W&B report.
Concluding thoughts
With this we have an simple easy to use framework for quick experimentation with LM finetuning. HuggingFace provides us with huge variety of state of the art Transformers and fastai facilitates configurable training loop with gret API. You are wellcomed to share your comments in dedicated fastai forums topic, try out fasthugs (I'm happy to here your opinions and accept feature requests) and finally open this notebook on Colab, select your task and try to set new best for the model.